
O Hadoop é uma ferramenta muito poderosa, marcando o mercado de dados por ser um verdadeiro ecossistema de bigdata. Ele foi lançado em 2006 com base em alguns estudos realizados pelo Google nos anos 2003 e 2004. Assim, essa ferramenta é capaz de fazer calculos em quantidades absurdas de dados e por isso se tornou uma referência no mercado. Então, vamos aqui falar das Top 25 Ferramentas do Hadoop, uma vez que seu ecossistema é modular e muito extensível. Veremos várias ferramentas, algumas nativas, outras embarcadas e outras que funcionam independentemente mas que têm um relacionamento de destaque.
Além do artigo Top 25 Ferramentas do Hadoop temos alguns outros falando sobre o tema de dados, gestão, kubernetes, DDD, devops, etc. Portanto, selecionamos alguns artigos que podem complementar essa leitura, caso seja de seu interesse:
- Banco de dados: Teorema CAP
- Os 14 tipos de bancos de dados
- Arquitetura Lambda e Arquitetura Kappa
- O Essencial do Hadoop
Sumário
- As TOP 25 ferramentas do ecossistema Hadoop
- 1 – Hadoop Distributed File System (HDFS)
- 2 – MapReduce
- 3 – YARN (Yet Another Resource Negotiator)
- 4 – Hive
- 5 – Pig
- 6 – HBase
- 7 – ZooKeeper
- 8 – Spark
- 9 – Sqoop
- 10 – Flume
- 11 – Oozie
- 12 – Kafka
- 13 – Flink
- 14 – Cassandra
- 15 – Avro
- 16 – Impala
- 17 – Presto
- 18 – Drill
- 19 – Tez
- 20 – Ambari
- 21 – Mahout
- 22 – Chukwa
- 23 – HCatalog
- 24 – Airflow
- 25 – Hue
- Conclusão de Top 25 Ferramentas do Hadoop
- Resenha do livro 'A arte de fazer acontecer'
- RSCSS
- O que é o INPC?
- Entendendo o Apache Spark
- Liderança Situacional em TI
- Não confio em quem não erra
- DORA Metrics
- Porque você já deveria estar usando Hashicorp Consul?
As TOP 25 ferramentas do ecossistema Hadoop
1 – Hadoop Distributed File System (HDFS)
O HDFS é o sistema de arquivos nativo do Hadoop. Ele é feito para lidar com multiplos nodes conectados através de um cluster. Os arquivos criados nele são quebrados e replicados em vários nós ao mesmo tempo. Assim, essa estrutura dá maior resiliência e desempenho na execução das consultas por meio do MapReduce.
2 – MapReduce
Além dele, o MapReduce é uma das estruturas mais poderosas do Hadoop. Assim ele funciona em conjunto com o HDFS para mapeamento dos dados e execução de cálculos em múltiplos nodes. Portanto a vantagem mais evidente dessa estratégia é que a computação pode ser dividida pela quantidade de nodes que o cluster têm com aqueles dados. Entretanto, o ponto negativo é que ele faz muita escrita e leitura em disco e, por conta disso, alternativas dentro do próprio sistema hadoop ganharam destaque ao longo do tempo.
3 – YARN (Yet Another Resource Negotiator)
Além do MapReduce há também o Hadoop Yarn, que antes da versão 2.x não existia. Então, até esse momento fazia o gerenciamento dos jobs a serem executados nos nodes de uma forma pouco flexível. Portanto, a partir do YARN foi possível utilizar fazer uso de outras ferramentas dentro do ecossistema hadoop.
Assim, o YARN é o gerenciador de recursos do Hadoop. Desse modo, ele verifica se um determinado node é capaz de executar determinado calculo, ele distribui as computações a partir do master e obtém através dos nodes slave.
4 – Hive
O Hive é uma infraestrutura de DW (DataWarehouse) para o ambiente do Hadoop. Desse modo, como o hadoop apresenta uma complexidade por depender de programação em Java, o Hive consegue abstrair parte dessa complexidade. Então, ele possui uma linguagen chamada HiveSQL e é baseada na HiveDDL.
Ele é construído para dados analíticos e não operacionais, portanto não é recomendado atualizar dados nele. O banco de dados padrão é o Derby e sua interface de uso é o Hue (web) ou o Beeline (CLI).
5 – Pig
O PIG é uma ferramenta do ecossistema do hadoop capaz de trabalhar com os dados numa infraestrutura de datawarehouse . Ela funciona como uma abstração do map-reduce, nativo do Hadoop, mas totalmente em memória. Ela possui uma linguagem própria para suas queries chamada Pig Latin. Além disso ela tem uma interface CLI chamada grunt e a Hue como interface web (igual a do Hive).
O PIG lida com vários tipos de dados como tuplas (que representam linhas de um banco de dados) ou bags (equivalente a tabelas ou collections). Embora não seja uma obrigação, é possível armazenar os resultados em disco, quando necessário.
6 – HBase
O HBase é um banco de dados feito para funcionar em um ambiente distribuído. O HB suporta escalabilidade horizontal, seus dados são semi-estruturados e ficam divididos dinâmicamento por entre os nodes. Além disso ele possui um conceito interessante chamado ‘Familia de Colunas’ que é uma coluna com sub-colunas para representar os seus dados. Entretanto a forma de acesso a ele não se baseia em SQL.
7 – ZooKeeper
O ZooKeeper é um sistema desenvolvido em Java que desempenha um papel fundamental no gerenciamento distribuído de configurações e na descoberta de serviços. O ZooKeeper adota um modelo de dados hierárquico semelhante a um sistema de arquivos, permitindo aos desenvolvedores armazenar e recuperar informações de configuração e detalhes de serviços. Com recursos avançados de sincronização e gerenciamento de eleição de nodos, ele assegura uma alta disponibilidade e tolerância a falhas. Além disso, o ZooKeeper pode ser utilizado junto ao Hadoop de modo a auxiliar na coordenação do cluster, eleição de líderes caso hajam quedas em nodos do cluster, monitoramento e configuração.
8 – Spark
O Spark é uma das mais poderosas aplicações relacionadas à bigdata nos dias atuais. Ela pode funcionar standalone (sem relação com o Hadoop), integrada com o Yarn substituindo o MapReduce ou apenas consumindo o HDFS. Essa solução lida com diversos aspectos da engenharia de dados e da ciência de dados em uma só estrutura. Além disso ela é programável em Java, Scala e Python, característica que dá a ela muitos adeptos. Por ela lidar com as computações em memória RAM sem realizar escritas em disco, o desempenho é bastante superior ao Hadoop.
9 – Sqoop
Sqoop é uma das ferramentas mais populares para injestão de dados no Hadoop. Seu nome vem de uma mescla entre SQL+Hadoop=SQoop. Então, ele é util para importação e exportação de dados de bancos de dados TSQL, como MySQL, Postgree, etc. Portanto ele se conecta através de um driver JDBC e oferece uma comand-line para a injestão. O Sqoop consegue lidar com 4 tarefas ao mesmo tempo, normalmente separando por blocos de IDs incrementais. Por padrão ele só obtem dados comitados e obtem os dados de modo incremental.
10 – Flume
O flume é uma ferramenta para injestão de dados não estruturados. Com ele é possível apontar para uma fonte de dados, definir um determinado processamento e indicar a saída dos dados. Ele é complementar ao Sqoop com a diferença da estrutura dos dados.
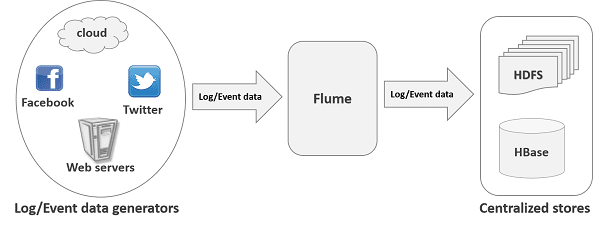
O Flume se baseia em dados de eventos (streaming) e possui uma estratégia de sink, que remove o evento de um canal (Channel) e garante que o destinatário está com ele.
Esses são alguns exemplos de origens de dados para o Flume
- Avro
- Spooling Directory
- Kafka
- NetCat TCP / UDP
- Syslog
- HTTP
Já esses são exemplos de destinos
- HDFS
- Hive
- Avro
- HBase
- ElasticSearch
- Kafka
- HTTP
11 – Oozie
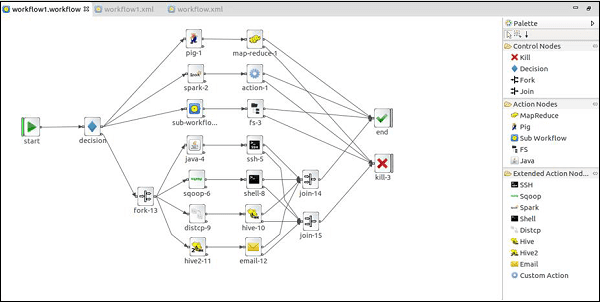
O Apache Oozie é um gerenciador de worklows (fluxos de trabalho) que funciona exclusivamente para o ecossistema hadoop. Ele se baseaia em DAGs (Grafos acíclicos dirigidos ou Directed acyclic graph), que são diagramas que não podem fazer loops ou retornar. Ele possui estruturas prontas para lidar com as ferramentas mais tradicionais do ecossistema, como MapReduce, Piog, Sqoop, Hive, Spark, e afins. Outra característica fundamental é a capacidade de lidar com agendamento para ingestão, processamentos e toda a manipulação dos dados.
12 – Kafka
O Apache Kafka é o mais popular sistema opensource de streaming de eventos. Ele foi desenhado para suportar volumes estonteantes de dados em 2010 pelo Linkedin mas que atualmente é mantido pela Apache Foundation. Além disso, ele funciona de modo independente do Hadoop, trabalhando de forma distribuída e escalável. E também funciona de modo ligeiramente parecido com RabbitMQ, por exemplo, tendo produtores e consumidores dos eventos. Esses eventos podem estar envolvidos com o Hadoop para uma maior potencialidade da arquitetura.
13 – Flink
O Flink é uma ferramenta especializada em tratamento de streamings de eventos. De certo modo ela traz características que competem com o Spark, mas, de modo geral o flink trabalha melhor com eventos do que o Spark. O Flink possui características como: Processamento de Streaming em Tempo Real, Tolerância a Falhas e Recuperação Automática, Processamento em Lote e em Tempo Real, Suporte a Dados de Estado, Processamento de Eventos Exatamente uma Vez (Exactly-once Processing), Integração com Ecossistema Apache e APIs Amigáveis e Libraries e suporte para Aprendizado de Máquina.
14 – Cassandra
Esse é o 14º do Top 25 Ferramentas do Hadoop. O Apache Cassandra é um banco de dados NoSQL criado po desenvolvedores Facebook e passou a ser mantido pela Apache Foundation em 2009. Ele foi construído para ser muito rápido, suportar alta escala de dados, e ser bom para leitura e para a escrita, ao mesmo tempo que é confiável. Ele pode ser utilizado junto ao Kubernetes e gerar uma escala dinâmica a medida que a demanda sobe. E pode também ser utilizado junto ao Hadoop.
Ele possui um esquema diferentes dos bancos tradicionais com uma KeySpace, dados disponibilizados com replicationFactor e familia de colunas, como o HBase. Além disso é possível operar uma uma linguagem SQL Like chamada Cassandra Query Language (CQL).
15 – Avro
Esse é um dos padrões de formato de arquivos utilizados nos ambientes de bigdata. Ele costuma fazer par com o formato Parquet por sua complementariedade. O formato Avro lida com estruturas de objetos com tipos, porém serializado em binário. O artigo Formatos de serialização para bigdata explora um pouco mais esse assunto.
16 – Impala
O Apache Impala é uma ferramenta opensource de datawarehousing, semelhante ao Hive (quarto da lista). Uma das principais características do Impala é sua capacidade de realizar consultas SQL diretamente nos dados, em vez de depender de extração e processamento prévio dos dados antes da análise. Ele usa a mesma sintaxe SQL padrão que a maioria dos usuários de bancos de dados e ferramentas de análise estão familiarizados, facilitando a adoção e a integração com sistemas existentes.
17 – Presto
O Presto é outra ferramenta integrada com o ambiente Hadoop para datawarehousing. Ele foi desenvolvido inicialmente pelo Fecebook em 2012 mas posteriormente doado a Presto Software. Ele se destaca por seu desempenho para consultas rápidas, por lidar com SQL para suas consultas, pela integração com HDFS, S3, MySQL, SQLServer, Cassandra, Mongo, etc.
18 – Drill
O Apache Drill é outro projeto que compete com o Hive, Impala ou Presto. Portando, trata-se de uma ferramenta capaz de ler arquivos e analisar como fonte para datawarehousing. Assim, ele é capaz de lidar com os principais formatos de arquivos utilizados no ambiente de dado, como Parquet, Avro, Orc, etc. Portanto, ele é integrável com estruturas como S3, MySQL, Cassandra, HBase, entre outros; além de ser totalmenet integrável com o Hadoop e HDFS.
19 – Tez
O Apache Tez tem por objetivo fazer computações de larga escala com velocidade e compensando os problemas do MapReduce. Ele se integra diretamente com o Yarn interferindo na alocação dos recursos do cluster Hadoop. O Tez é capaz de executar as consultas ao mesmo tempo que lida com fluxos ou pipelines por meio de DAGs (Directed Acyclic Graph).
20 – Ambari
O Apache Ambari é uma ferramenta web que ajuda na manitenção do ambiente de bigdata. Então, trata-se de uma ferramenta onde é possível instalar, configurar e monitorar as ferramentas envolvidas no ambiente desejado. Portanto, só de observar essa lista é notável que muita coisa diferente pode ser utilizada em conjunto e o Apache Ambari pode ajudar bastante.
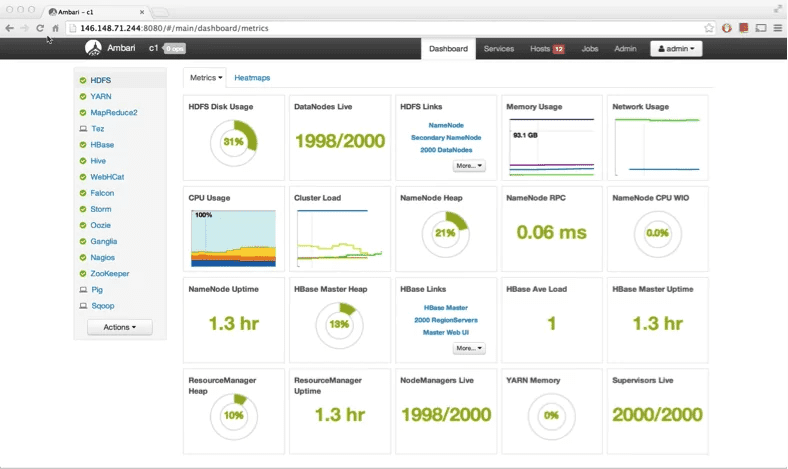
Além disso, os recursos que se destacam nele são instalação e configuração simplificada de clusters hadoop, gerenciamento dos serviços, monitoramento do desempenho, configuração centralizada, features de segurança e integração via APIs.
21 – Mahout
Essa é um biblioteca opensource escrita em java para trabalhar com inteligencia artificial. Ela é focada em aprendizado não supervisionado e recomendações. Ela implementa as algorítmos mais populares do tema. Ele foi desenvolvido inicialmente para funcionar com o Hadoop mas se expandiu e foi disponibilizado para ambientes fora desse ecossistema. Segue um pequeno trexo de código escrito em java como exemplo do uso prático para recomendações:
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class MovieRecommendationExample {
public static void main(String[] args) {
try {
// Carregar o conjunto de dados a partir de um arquivo CSV
DataModel dataModel = new FileDataModel(new File("ratings.csv"));
// Definir a similaridade entre os itens com base na correlação de Pearson
ItemSimilarity itemSimilarity = new PearsonCorrelationSimilarity(dataModel);
// Definir a vizinhança dos usuários mais próximos (neste caso, usamos 2 vizinhos)
UserNeighborhood userNeighborhood = new NearestNUserNeighborhood(2, itemSimilarity, dataModel);
// Criar o recomendador com o algoritmo de filtragem colaborativa baseado em itens
Recommender recommender = new GenericItemBasedRecommender(dataModel, itemSimilarity);
// Fazer uma recomendação para o usuário 1 (por exemplo)
List<RecommendedItem> recommendations = recommender.recommend(1, 3);
// Exibir as recomendações
System.out.println("Recomendações para o usuário 1:");
for (RecommendedItem recommendation : recommendations) {
System.out.println("ID do filme: " + recommendation.getItemID() + ", Valor da recomendação: " + recommendation.getValue());
}
} catch (IOException | TasteException e) {
e.printStackTrace();
}
}
}22 – Chukwa
Esse é um sistema específico para coleta de dados de log, armazenamento e análise. Como ele funciona em conjunto com o hadoop, ele suporta uma quantidade gigantesca de dados. Além disso ele é um sistema extensível, dando abertura para plugins específicos.
23 – HCatalog
Essa é uma ferramenta responsável pelo catálogo de dados. Portanto, ela funciona no ecossistema hadoop mantendo metadados por entre as diferentes ferramementas associadas. Assim, com ela é possível gerenciar esquema de tabela, tipo de dado, localização dos dados, por entre as diferentes ferramentas. Ela é capaz de lidar com formatos como Avro, RCFile, entre outros. Além disso ela suporta queries SQL ou pig latin. Por fim, ela funciona como uma camada de abstração em cima de toda a infraestrutura do hadoop.
24 – Airflow
O Apache Airflow é uma ferramenta para orquestração de fluxos de trabalho (workflow) voltado a dados. Embora ele não tenha uma relação direta com o Hadoop, ele é importante para o ecossistema de bigdata, podendo ser integrado com o banco de dados HDFS.
Ela é uma ferramenta notável por sua flexibilidade e por trabalhar diretamente com python, que facilita bastante. Ele trabalha com diversas dags para cumprir o seu objetivo, além de uma interface gráfica que facilita bastante.
25 – Hue
O HUE ou Hadoop User Experience é uma ferramenta web que se integra com o ecossistema hadoop dando a ela maior capacidade de manipulação. Inicialmente desenvolvida pela Claudera ela é atualmente mantida pela Apache Foundation, como a maior parte das ferramentas desse ecossistema.
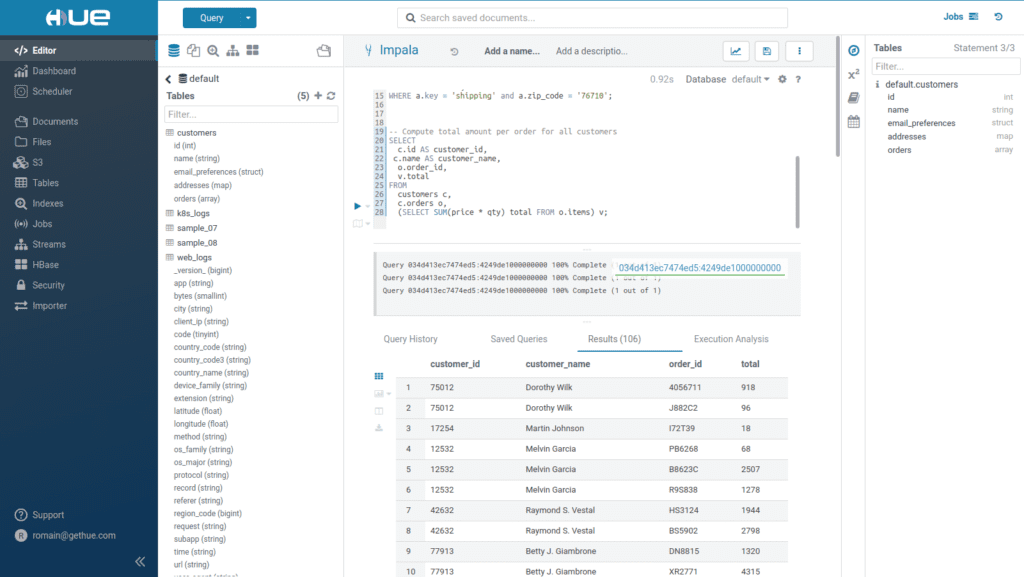
Com o Hue é mais fácil trabalhar com o hadoop podendo manipular facilmente os arquivos do HDFS, editar consultas SQL, fazer agendamento de workflows, interagir com HBase, Impala, Pig ou Sqoop, ou mesmo gerenciar o cluster.
Conclusão de Top 25 Ferramentas do Hadoop
O Hadoop é o pai do bigdata. Ele possui um ecossistema próprio com diversas ferramentas com propósitos diferentes. Aqui em Top 25 Ferramentas do Hadoop vamos dar uma visão geral sobre diversas dessas, tais como Hive, Pig, Sqoop, Kafka, Zookeeper. Note que nem todas essas ferramentas são dependentes do Hadoop, mas são relevantes para o ecossistema e por isso aparecem na lista.

Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
