
Quando falamos de engenharia de dados não há como não pensar do Apache Spark. Atualmente é a ferramenta mais completa no tratamento de dados. Entendendo o Apache Spark: Até pouco tempo o Hadoop reinava mas ele precisava de um grande conjunto de ferramentas para seu uso. Além disso, o Spark traz uma nova estratégia para lidar com filtragem, em substituição ao Hadoop MapReduce, graças ao progressivo barateamento das memórias. O artigo Entendendo o Apache mostrará diversos aspectos como: Arquitetura, lazy Evaluation, DAGs e afins.
O artigo Entendendo o Apache Spark é focado em dados: o blog fala sobre temas como devops, arquitetura, gestão, desenvolvimento e afins. Assim, para complementar o tema, segue alguns artigos relacionados, que não são obrigatórios, mas podem ajudar a dar contexto.
- O Essencial do Hadoop
- Arquitetura Lambda e Arquitetura Kappa
- Banco de dados: Teorema CAP
- Os 14 tipos de bancos de dados
- O básico de Apache Airflow
- Formatos de serialização para bigdata
Sumário
- O que é Spark
- Entendendo o Apache Spark: A Arquitetura
- Bibliotecas e extensões
- Conclusão de Entendendo o Apache Spark
- Top 10 Service Discovery
- Domain Driven Design: Afirmações
- Usando um "Github" onpremise
- Domain Driven Design estratégico
- Utilizando computação paralela massiva para cálculos pesados (C++ AMP)
- Diferença entre TLS e mTLS: O que você tem que saber
- 7 APIs públicas, gratuitas e de qualidade
- Docker, Docker Swarm e Kubernetes
O que é Spark
O Apache Spark é um framework opensource poderoso, desenvolvido na Universidade da Califórnia e mantido pela Apache Foundation. Ele é especializado em tratamento de dados em larga escala. O Apache Spark resolve os problemas mais prementes de sua época, em especial do Hadoop e seu ecossistema com ferramentas como o Hadoop MapReduce.
O Hadoop funcionava ao lado de diversas ferramentas de mercado como Pig, Hive, Sqoop, Flume e afins. Já o Spark consolidada diversas dessas características num só produto, algo que facilita muito a manutenção. Entretanto o Spark ainda assim suporta extensão se necessário, portanto ele é integrável com Kubernetes, Apache Mesos, AWS S3, HBase, Cassandra, HDFS, Yarn, entre outros.
O Spark se tornou cada vez mais conveniente a medida que as memórias se tornaram mais baratas. O uso de disco, que era comum em alguns procedimentos do Hadoop MapReduce, tornava a solução menos performática. Ao contrário, o Spark trabalha em memória ou em disco, se necessário, aumentando em 100x.
Entendendo o Apache Spark: A Arquitetura
O Spark é uma solução escrita em Scala, mas sabe lidar com outras linguagens como Java, Python, R, entre outras implementações. Isso traz uma vantagem mercadológica por reduzir a curva de aprendizado para iniciantes.
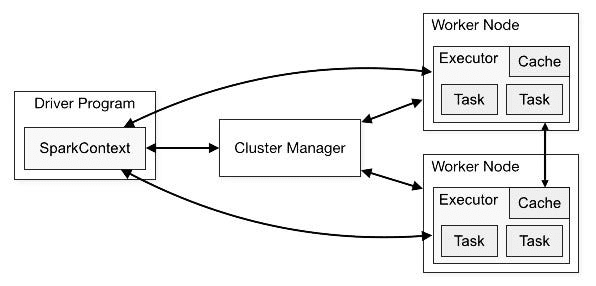
Além disso o Apache Spark é formado por uma série de componentes feitos para dar o maior desempenho possível e lidar com as diferentes complexidades dos dados. Vamos falar um pouco sobre eles a seguir.
Driver Program
O Driver é núcleo cerebral do Spark. Ele é responsável por coordenar a execução do aplicativo spark, dando a ele um contexto, com seu startup configurado. Esse contexto tem autorização para executar computações no Spark.
Após isso, o driver subdivide a application em diversas tarefas menores, que podem ser executadas em diferentes nodes. Ao mesmo tempo ele cria uma DAG (Grafo Acíclico Direcionado) que representa o fluxo contido na spark application.
E depois as tarefas são enviadas para os executores, de acordo com a alocação que parece adequada para ele. Por fim o driver coleta e consolida o resultado.
SparkContext
Já introduzimos o SparkContext ao explicar o Driver Program. Acontece que após a versão 2.0 o Spark passou o ter o SparkSession, que abstrai o Spark. Assim, é uma recomendação que se use o SparkSession ao invés do SparkContext.
Portanto, o SparkContext é responsável por definir qual é a melhor estratégia para alocação e gerenciamento dos recursos (RAM, CPU, nodes, etc.). Se o Spark estiver rodando no Yarn mode ou com o Mesos, por exemplo, o sparkcontext também vai gerir o ambiente em que está.
Cluster Manager
O ClusterManager é responsável por gerenciar recursos de todo o cluster e não apenas do contexto. Ele tem a função de alocar recursos para as aplicaçõe, gerenciar os executors, lidar com falhas e garantir resiliência do ambiente bem como seu monitoramento.
Assim, há alguns cluster managers comuns, tais como: Standalone (para desenvolvimento), Apache Mesos (sistema de orquestração), Hadoop Yarn (funcionando dentro do hadoop, em substituição ao MapReduce) e o Kubernetes (principal orquestrador de containers do mercado).
Executors
Os executors são os responsável pela real execução das tarefas que foram solicitadas pela SparkApplication através do DriverManager. Então, um node do Spark pode ter um ou mais executors, que variam de acordo com a configuração definida, em alinhamento com os requisitos dessa maquina. Assim, as tarefas que fazem parte de uma aplicação spark, são alocadas nos diferentes executors.
Desse modo, os executors são responsáveis não somente pela execução, mas também pelo armazenamento em memória RAM ou em disco, pelo caching, pelo gerenciamento dos recursos num nível micro, e também pela tolerância a falhas também em nível micro.
Resilient Distributed Datasets (RDDs)
Primeiro vamos falar das partições do Spark. O Cluster é configurado para lidar com segmentos de memória chamados de partições. Se gerenciado de maneira incorreta é possível que a memória fique fragmentada com diversos arquivos pequenos quando não deveria. Não vamos falar em detalhes de boas práticas nesse sentido, mas entenda que é importante ter certo conhecimento desse detalha quando o cenário é complexo.
Pois bem, o RDD (Resilient Distributed Dataset) é a estratégia nativa do Spark para lidar com documentos e fazer uma alocação inteligente nas partições. Esse modelo é o mais fundamental, porém a partir da verão 2.0 do Spark passou-se a utilizar abstrações em cima desse modelo, como os Spark DataFrame e Spark DataSet. Para conhecimento, essas são algumas características de ambos e siga Entendendo o Apache Spark.
DataFrame
- Estrutura de dados tabular com colunas nomeadas.
- API rica para manipulação de dados estruturados e semiestruturados.
- Não possui tipagem forte em todas as linguagens (Scala e Java têm tipagem forte).
- Oferece otimizações de consulta baseadas no Catalyst Optimizer.
- Integração total com Spark SQL para execução de consultas SQL.
- Mais simples e amplamente utilizado para análise de dados
Dataset
- Estrutura de dados distribuída, imutável e com tipagem forte.
- API ainda mais expressiva com funções de programação funcional de alto nível.
- Tipagem forte em todas as linguagens (Scala, Java e Python).
- Oferece otimizações de execução e tratamento de dados semelhantes ao DataFrame.
- Maior controle sobre a tipagem de dados e transformações mais seguras.
- Integração completa com todas as linguagens nas versões mais recentes do Spark (a partir do Spark 2.3).
Lazy Evaluation: Transformações e Ações
O Spark, em última instância, tem a função de manipular dados. Por exemplo podemos ter uma lista com todos os salários de todos os brasileiros. Descobrir uma média de todos eles, ou média por estado, ou qualquer outro cálculo, certamente seria atribuição do Spark.
Ocorre que há dois tipos de manipulações nos dados: as transformações e as ações. As transformações geram alterações no posicionamento ou estrutura, com cálculos mais simples e otimizados que não exigem varredura dos dados. Por exemplo, uma ordenação ou um agrupamento, são transformações. Em contrapartida há as ações, que agem sobre todos os dados: como numa soma ou uma média.
Acontece que o Spark tem uma inteligência que acumula as transformações e a executa no momento em que há uma ação. Na verdade é um pouco mais complexo, mas isso representa bem a ideia. Entenda que o plano de execução da query é representado por uma DAG considerando tudo o que comentamos até agora.
DAG Scheduler
Quando o driver instancia um SparkContext e as tasks são distribuídas para serem trabalhadas pelos executors é criado um plano de execução. Seguindo o item anterior, note que há o lazy evaluation e consequentemente a construção de uma DAG que representa o plano de execução.
Pois bem, nesse momento há o plano lógico das transformações que são estruturadas para que a execução de fato seja a mais otimizada possível. O DAG Scheduler é o mecanismo responsável por agendar as execuções deles.
Task Scheduler
Esse é o agendador das tarefas definidas para execução por uma Executor. Ele considera a disponibilidade de recursos e os dados localmente disponíveis para otimizar a alocação de tarefas.
Memory Manager
Assim, esse é um dos componentes mais fundamentais do Spark, responsável pela alocação e gerenciamento da memória no cluster. Portanto, há no Spark uma estrutura de heap, onde os objetos mais globais e estáticos ficam disponíveis. Desse modo, essa estrutura é básica e gerenciada pelo Garbage Collecor da JVM. Já o off-heap tem os objetos não gerenciados pelo garbage collector, mas sim pelo próprio Spark de modo a criar otimizações particulares.
Data Sources e APIs
O Spark oferece suporte a várias fontes de dados, incluindo HDFS, sistemas de arquivos locais, bancos de dados JDBC, formatos de arquivos comuns (como CSV, JSON, Parquet) e muito mais. Ele também fornece APIs em várias linguagens de programação (Scala, Java, Python e R) para facilitar o desenvolvimento de aplicativos.
Bibliotecas e extensões
No passado quando se trabalhava essencialmente com Hadoop era comum trabalhar com uma diversidade de aplicações diferentes para organização do ambiente de bigdata. Já no Spark a coisa é um pouco mais simples: há bibliotecas que expandem as capacidades do produto.
Algumas das bibliotecas mais conhecidas são:
- Spark Streamming para manipulação de dados em tempo real ou near-real-time
- GraphX para tratamento de grafos
- SparkSQL para utilização de queries SQL-like
- MLib para lidar com aprendizado de maquina
- Delta Lake para biblioteca que dá características ACID, controle de versão e maior consistência para os dados
- Spark NLP para para processamento de linguagem natural (NLP) com suporte a várias tarefas de NLP, como análise de sentimento, reconhecimento de entidades nomeadas, classificação de texto, entre outras.
- Spark-GPU para otimizar analises utilizando a GPU, muito útil para machine learning
Há diversas outras, mas com as bibliotecas acima já dá para se divertir muito.
Conclusão de Entendendo o Apache Spark
O Apache Spark atualmente é a principal ferramenta na computação distribuída quando o assunto é bigdata. Diferentemente do passado hoje há um mercado muito vibrante com concorrentes, mas não tiram o brilho desse. Ele suporta linguagens de programação diferentes, algo fundamental para atrair programadores, engenheiros ou cientistas de dados. Suas estratégias internas são rebuscadas, como é o caso da LazyEvaluation e suas DAG’s criadas sob medida. Além disso ele possui diversas bibliotecas públicas ao invés do tooling do Hadoop que tinha uma manutenção complicada. O artigo Entendendo o Apache Spark explora um pouco de tudo isso.

Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
