
Vamos falar apenas o essencial do Hadoop. Essa ferramenta ou framework levou o mercado de dados a outro patamar. Na época em que surgiu, para realizar computações com grandes conjuntos de dados era necessário um computador muito poderoso. Assim, com o Hadoop passou a ser possível trabalhar com um exército de maquinas mais fracas.
Portanto o artigo “O Essencial do Hadoop” falará um pouco sobre a história do bigdata, sobre o hadoop e seus componentes internos, além de falar um pouco sobre o ecossistema gerado ao redor dele. Além disso, aqui no blog temos alguns artigos voltados para o tema de dados, que podem ser complementares a sua leitura:
Sumário
- Bigdata
- O que é o Apache Hadoop
- O Essencial do Hadoop: Outros pontos interessantes
- Conclusão de O Essencial do Hadoop
- Architectural Decision Record
- O básico de Apache Airflow
- CSS para o BEM - Block Element Modifier
- RSCSS
- Como funciona o bitcoin?
- Injeção de dependência ou Inversão de Controle
- Princípios e Acrônimos: SPOT, DRY, AHA, etc.
- O que há de novo no SharePoint 2016?
Bigdata
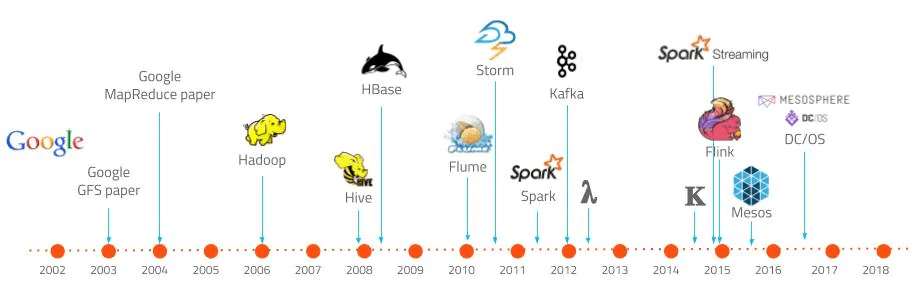
Inicialmente, em meados de 2000, Douglas Laney observou tendências no mercado em relação aos dados: Aumento do volume (zetabyte, terabyte), da demanda por velocidade (em lote, realtime ou near-realtime [streaming]) e pela estrutura do dado, ou variedade (estruturado, semi-estruturado ou não estruturado). Isso é conhecido como 3Vs. Não é incomum encontrar outros V’s como veracidade, valor e até outros. Mas prefiro me concentrar nesses.
Em torno de 2005 criou-se o termo bigdata com base nos conceitos criados do Laney. E além disso, nasceu em 2006 o Hadoop, baseado nos conceitos do GFS e MapReduce criados pelos engenheiros do Google.
O que é o Apache Hadoop
O Apache Hadoop é um framework opensource de computação e armazenamento de dados de forma distribuída e para larga escala. Ele possui estruturas específicas para suportar grandes volumes de dados, armazenados em vários nodes mas com tolerância a falhas.
O Hadoop possui 3 componentes essenciais para seu funcionamento: HDFS, o Yarn e o MapReduce. Há também um ecossistema secundário de aplicações que funcionam ao redor desses componentes, mas não serão profundamenta tratados aqui.
Arquitetura do Hadoop
Assim, a arquitetura do Hadoop é a master-slave. Portanto o nodo master tem por objetivo gerenciar todo o cluster, alocar ou manter documentos, gerenciar as tarefas solicitadas, observar a saúde dos nodes e, se for o caso, considerá-lo fora do ar e eleger um substituto. Porém, antes da versão 2.0 do Hadoop não existia o Yarn e o gerenciamento dos recursos era feito de modo inferior.
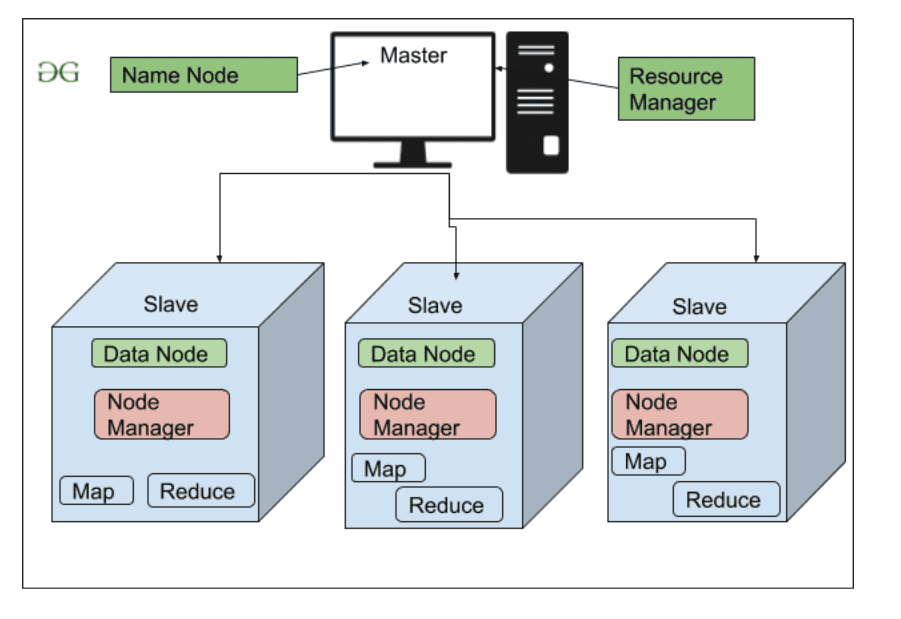
Assim ele foi construído para lidar com massas expressivas de dados e processados por Batch de modo distribuído. O uso para pequenos dados pode ser útil para estudos ou para ensaios mas não faz sentido econômico para um caso real: Isso é entender o Essencial do Hadoop.
Nodo Master
Nodo (ou nó) responsável pelo gerenciamento do cluster Hadoop.
- Namenode: gere o HDFS, mantém metadados, logs, mantém arquivos.
- JobTracker: distribui tarefas de map e reduce entre os nodos
- TaskTracker: É quem efetivamente executa as tarefas.
No Hadoop 2.x o Yarn substitui/engloba parte dessas funcionalidades.
Nodo Slave
Nodo (ou nó) responsável pelo armazenamento dos dados e execução das computações.
- Datanode: Mantém dados, replica blocos.
- Ativo: Datanode que está funcionando na prática, executando ações e replicando blocos
- Stand-by: Datanode que só aparece se houver queda de outro datanode.
Heartbit
Os nodos enviam uma informação de controle para o master-node indicando que estão disponíveis. Caso essa mensagem de controle não seja enviada, o master-node se o considera fora do ar e seus dados são realocados para outro node.
HDFS – Hadoop Distributed File System
Já o Hadoop funciona com base em um sistema de arquivos feito sob medida para ele, o DFS do Hadoop, ou HDFS. Porém, diferente da maioria dos sistemas de arquivos, ele considera que os documentos serão quebrados em nodes para garantir redundância e facilitar o trabalho do map-reduce futuramente.
Assim, o HDFS divide os documentos em blocos de 128MB por padrão (que pode ser alterado). Quando colocamos um arquivo de 64MB no HDFS, ele ocupa 128MB se estivermos configurados dessa forma. Por outro lado, se o arquivo tiver 256MB, ele é alocado em 2 blocos de 128MB.
Além disso, considere que a infraestrutura do hadoop terá vários nodes (Por padrão um arquivo criado no hadoop é replicado em 3 nodes). Então, um arquivo de 64MB aloca 128MB (se a configuração estiver no padrão) em 3 nodes, ou seja, ocupando um total de 384MB. Porém é possível alterar o factor de replicação (ReplicationFactor) caso seja interessante.
O que ocorre quando um datanode cai?
O namenode entende que há indisponibilidade e reajusta a infraestrutura de modo que os dados estejam alocados em outros nodes, garantindo o estado desejado de 3 para o fator de replicação. Isso é fundamental para que não sobrecarregue o map-reduce, além de garantir o máximo de disponibilidade possível para o ambiente.
Yarn
O Yarn (Yet Another Resource Negotiator) foi introduzido na versão 2.x do Hadoop. Com o Yarn ferramentas terceiras podem ser utilizadas em susbtituição ao map-reduce, por exemplo, dando maior modularidade para o produto.
Ele é organizado em 3 componentes:
- ResourceManager (RM): Gerencia os recursos e escalona as computações. Mantém informações de desempenho, memória, processador, etc. dos nós do cluster.
- NodeManager (NM): Esse recurso fica disponível em cada nó do cluster. Ele é o responsável por gerenciar a execução das tasks, bem como saber se a task requerida é exequível no nodo em questão.
- ApplicationMaster (AM): Recurso responsável por gerenciar as aplicações instaladas no cluster. Ele negocia recursos com o ResourceManager. Ele também é capaz de lidar com reagendamentos em casos de falha.
MapReduce
Já o MapReduce é um recurso construído especialmente para executar tarefas dentro de uma infraestrutura distribuída de dados. Assim, se o dado está dividido em vários nodes, o hadoop precisa descobrir onde estão esses dados. Assim, a partir dessa descoberta as tarefas pode ser realizadas.
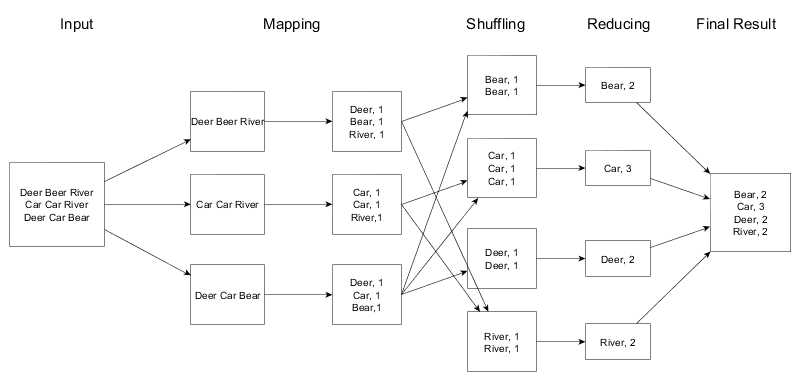
Então vamos tomar como referência a imagem acima: Nela vamos considerar que há um arquivo de input. Assim, a partir desse input vamos fazer um agrupamento contando a incidência das palavras.
Fase 1: Map
Nessa fase vamos descobrir em quais nodos estão os dados e de que modo. Note que ele encontrou no primeiro nodo 1 incidencia de Deer, 1 de Bear e 1 de River.
Fase 2: Shuffle
Nessa fase faz-se uma organização do que foi encontrado de modo a facilitar o processo de Reduce.
Fase 3: Reduce
Nessa fase há o agrupamento dos dados a fim de trazer algum resultado específico. No exemplo em questão faz-se o somatório das incidências. Incialmente a soma é feita em cada nó, e depois são agrupados num so resultado.
A lógica é bastante simples, mas é importante notar que a construção de map-reduce demanda a escrita de códigos em Java ou outra linguagem compatível com JVM. Além disso nem todas as tarefas demandam o uso do reduce ou do shuffle, cabendo ao desenvolvedor/engenheiro contruir do modo adequado.
Veja um exemplo de código em Java que executa a classe WordCount (Contagem de palavras). Podemos dizer que esse é um ‘HelloWorld’ do Hadoop.
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountApplication {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration hadoopConfiguration = new Configuration();
Job hadoopJob = Job.getInstance(hadoopConfiguration, "WordCount");
hadoopJob.setJarByClass(WordCountApplication.class);
hadoopJob.setMapperClass(WordCountMapper.class);
hadoopJob.setCombinerClass(WordCountReducer.class);
hadoopJob.setReducerClass(WordCountReducer.class);
hadoopJob.setOutputKeyClass(Text.class);
hadoopJob.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(hadoopJob, new Path(args[0]));
FileOutputFormat.setOutputPath(hadoopJob, new Path(args[1]));
System.exit(hadoopJob.waitForCompletion(true) ? 0 : 1);
}
}A classe a seguir é o Mapper, que obtem as expressões corretas dos nodes e os prepara para a redução.
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable oneIntegerWritable = new IntWritable(1);
private Text word = new Text();
public void map(Object inputKey, Text inputValue, Context context) throws IOException, InterruptedException {
StringTokenizer stringTokenizer = new StringTokenizer(inputValue.toString());
// for each token in the input data set.
while (stringTokenizer.hasMoreTokens()) {
//set the Word to the current token in hand.
word.set(stringTokenizer.nextToken());
// create (KEY_OUT, VALUE_OUT) pair.
context.write(word, oneIntegerWritable);
}
}
}Por fim, o código a seguir faz o Reduce. (Fonte do código: Repositório do github )
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer {
private IntWritable reducedIntegerWritable = new IntWritable();
public void reduce(Text inputKey, Iterable inputValues, Context context) throws IOException, InterruptedException {
int wordCount = 0;
// for each value calculate sum of occurrences to have a word count.
for (IntWritable value : inputValues)
wordCount += value.get();
// create (KEY_OUT, VALUE_OUT) pair.
reducedIntegerWritable.set(wordCount);
context.write(inputKey, reducedIntegerWritable);
}
}O Essencial do Hadoop: Outros pontos interessantes
Distribuições Hadoop
A Hadoop tem uma estrutura altamente modular, em especial após a implementação do YARN (hadoop 2.x ou superior). Por conta disso, há no mercado diversas versões diferentes do hadoop com distribuições próprias. Isso se assemelha muito ao próprio Linux. A distribuição mais popular hoje em dia é a da Claudera, mas há distribuições da AWS, Hortonworks, KarmaSphere, Pentaho, Tresada e etc.
Ecossistema Hadoop
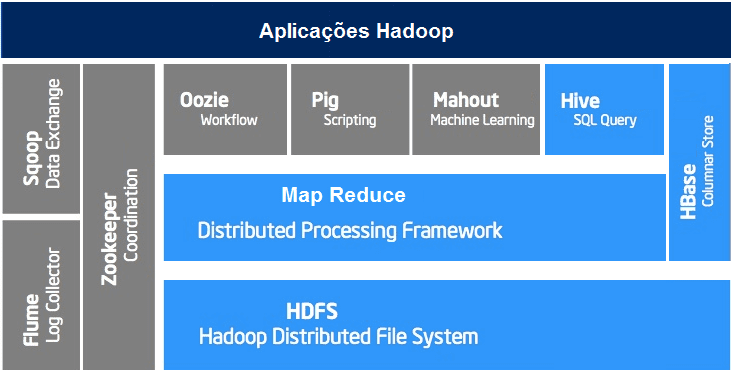
O Hadoop ganhou muito com o Yarn, por passar a ser possível a inserção de novos módulos capazes de executar suas computações de modo diferente. Um destaque especial para o Apache Apark que executa as computações em memória sem guardar dados intermediários em disco, ao contrário do MapReduce. Mas há também o Zookeeper, Flume, Chukwa, Pig, Hive, Avro, Mahout, HCatalog, HBase, Oozie, Pig, Sqoop, Cassandra, etc.
Conclusão de O Essencial do Hadoop
O Hadoop materializou o conceito de bigdata e modificou toda a forma em que o mercado encara os dados. Ele tem uma arquitetura muito bem feita para suportar grandes volumes. Ele possui um sistema de arquivos distribuidos, o HDFS, que lida com esse problema. Além disso há o map-reduce que em alinhamento com o HDFS produz cálculos em massas inacreditáveis de dados: Ainda que utilizando vários computadores de desempenho mediano. Por fim o Yarn possibilizou uma maior extensibilidade do produto, dando abertura para novas ferramentas como o Zookeeper, Pig ou Spark. O Essencial do Hadoop dá uma visão panorâmica sobre o produto além de pequenos exemplos.
Referências
- Hadoop: fundamentos e instalação
- Hadoop – Architecture
- Apache Hadoop HDFS Architecture
- Hadoop Architecture Explained-The What, How and Why

Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
