
Temos muitos dados a disposição: Muitos! Se você observar a quantidade de redes sociais, aplicações, APIs, bancos de dados, sistemas, etc. Temos também muitos formatos e diferentes exigências de velocidade no tratamento desses. Pois bem o artigo Arquitetura Lambda e Arquitetura Kappa fala sobre as principais abordagens modernas no tratamento desse tipo de problema.
Aqui no blog temos diversos artigos que falam sobre dados, arquitetura, devops, kubernetes e afins. Recentemente escrevemos os artigos Banco de dados: Teorema CAP e Os 14 tipos de bancos de dados que podem ser complementares a esse sobre Arquitetura Lambda e Arquitetura Kappa.
Sumário
- Um pouco da história: Big data
- Como vencer o teorema CAP
- Questionando a arquitetura Lambda
- Conclusão de Arquitetura Lambda e Arquitetura Kappa
- Como funciona a criação bitcoins ‘do nada’?
- Instalando o DeepSeek em casa
- As 7 dimensões do Domain Driven Design
- Como exibir uma lista de um site SharePoint em outro site SharePoint?
- OOCSS (Object-Oriented CSS)
- Docker, Docker Swarm e Kubernetes
- Integração Contínua Cloudless
- O básico de Apache Airflow
Um pouco da história: Big data
Douglas Laney no inicio dos anos 2000 trabalhava no Garner. Ele foi um importante estudioso sobre dados e começou a pensar sobre o tema e as tendências patentes no momento:
1 – O Volume dos dados tende a crescer muito. A digitalização de documentos físicos, a construção de novos equipamentos, a contínua necessidade da tecnologia para a sustentação dos novos negócios e o progressivo barateamento e capacidade das tecnologias de armazenamento, juntos, contribuiram para os insights do Douglas.
2 – A Velocidade tendia a crescer. Ele era muito visionário por que no período não tinhamos smartphones, tablets, netflix, etc. mas ele previa que o aumento do volume bem como a interconectividade do mundo aumentaria a necessidade de velocidade.
3 – O terceiro item é a Variedade, ou seja, a forma do dado tenderia a se especializar, com isso gerando variantes. Mas por outro lado o formato do canal se solidificaria, reduzindo o uso do formato analógico pela substituição digital.
Douglas entendia que essas características somadas criaria a necessidade de estruturas que ainda não existiam, mas que não poderiam ser tratadas pelos bancos de dados da época.
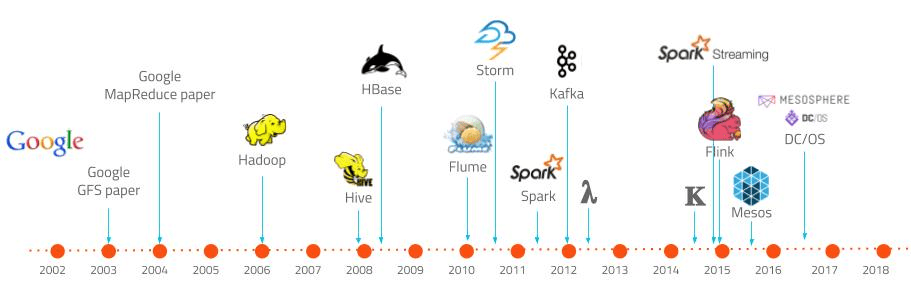
Já em 2005 Roger Magoulas e Doug Cutting simpolificaram os conceitos trabalhados anteriormente através do nome de Big Data. Note, olhando a timeline acima, que papers importantes do Google surgiram antes de 2005, e logo após nasceu o Hadoop.
O Hadoop é a materialização dos conceitos levantados pelo Douglas Laney, sendo uma ferramenta que efetivamente suportou volume, variedade e velocidade.
Como vencer o teorema CAP
O teorema CAP (ou Teorema de Brewer, ou ainda Teorema de Consistência de CAP) disserta sobre os diferentes tipos de bancos de dados e suas características essenciais. O Teorema indica que os bancos podem ser: focados em consistência; focados em disponibilidade do dado; ou focados na tolerância a partições. Para o Brewer, nenhum banco pode ter as 3 características ao mesmo tempo: pode no máximo duas.
Pois bem, Nathan Marz em 2011 escreveu um artigo chamado Como vencer o teorema CAP. No artigo ele sugere um estrutura arquitetural que seja capaz de suportar as 3 características ao mesmo tempo. Nathan concorda que o Teorema CAP é algo da natureza, mas que os projetos de dados tentam lidar com dois problemas ao mesmo tempo: (1) a mudança de estado dos dados e (2) a inserção incremental dos dados que atualizam o estado. Para ele é fundamental segregar as duas complexidades.
A arquitetura Lambda
Então o autor sugere que o tratamento de dados se de utilizando 3 diferentes camadas: (1) Batch layer, (2) a Speed Layer e a (3) Serving Layer. Elas juntas podem resolver o problema levantado.
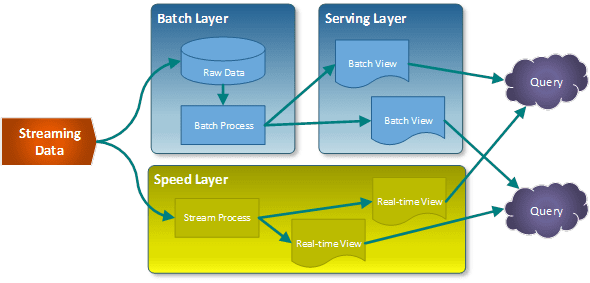
Essencialmente o fluxo de dados de entrada pode entregar um streming, ou seja, um fluxo constante de dados, ininterrupto. Esses dados são disponibilizados para ambas as camadas, mas vamos explicar uma por vez.
A Batch Layer ou camada de lote lida com dados agrupados ao longo de um tempo. Imagine que um processo desse rode uma vez por dia para gerar somatórios, produtórios e outros calculos de agrupamentos. Essa camada faz isso e apenas isso. Não há mistério.
O Batch faz um trabalho completo, de tempos em tempos. Essa camada não é de tempo real, e o uso dela precisa levar isso em consideração. Já a Speed Layer, ao contrário, trabalha com todos os dados que chegam, em tempo real.
A Serving Layer pode funcionar de diferentes modos. Ela pode existir apenas para a batch layer, apenas para a speed ou para abas. O fato é que ela estrutura o dado para a exposição para as aplicações, relatórios, etc. que queiram consumir.
Questionando a arquitetura Lambda
Jay Kreps foi um estudioso do padrão proposto por Nathan e sugeriu uma alternativa conforme seu artigo chamado Questioning the Lambda Architecture. No artigo ele comenta que o padrão Lambda é interessante, mas ele carrega alguns problemas, como por exemplo: a necessidade de ter a lógica complexa de batch sendo replicada no speed. Muitas vezes tecnologias diferentes são utilizadas no cenário.
Veja o diagrama abaixo que exemplifica uma arquitetura real que utiliza a arquitetura Lambda como base. Os dados são alimentados através de um tópico Kafka que são consumidos pelo Hadoop que cumpre o papel de batch; e pelo Storm que cumpre o papel de speed. Por fim, tabelas tradicionais são geradas como serving layter para o speed e para o batch.
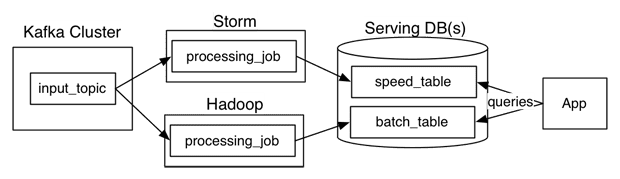
Note que nessa abordagem é importante criar a mesma lógica no storm e no hadoop. As atualizações também, e isso pode ser um desafio. A sugestão do Jay é a utilização de um modelo que ele chamou de Arquitetura Kappa.
A Arquitetura Kappa
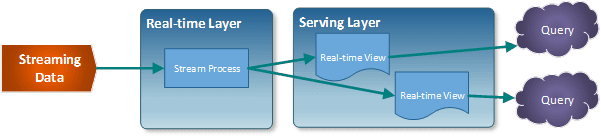
A Arquitetura Kappa, na prática, ignora a existência da camada Batch e tem apenas as camadas Speed e Serving, desse modo, há apenas um ponto de manutenção. Ela apresenta uma estrutura de implementação mais simples, embora ela tenha como ônus a perda do histórico da camada Batch.
Conclusão de Arquitetura Lambda e Arquitetura Kappa
Ambas as arquiteturas são capazes de lidar com dados massivos, volumosos etc. com características particulares. O uso da Lambda é o mais popular, mas que exige mais tecnologias envolvidas, tem uma manutenção mais difícil; ao contrário da Kappa que simplifica tudo, porém pode não ter o histórico dos dados. Como de costume, trata-se de analisar um caso em específico para saber qual arquitetura se parece mais adequada.

Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
