Sumário
- Trabalhando com cálculos diretamente na placa de vídeo
- Comparando computação tradicional com a computação paralela massiva na placa de vídeo
- Entendendo o Cenário
- Configuração do computador(CPU)
- Configuração da Placa gráfica (GPU)
- Algorítmo
- Método Principal
- Tempo de execução
- Conclusão
- ITCSS (Inverted Triangle CSS)
- Como funciona a criação bitcoins ‘do nada’?
- 7 APIs públicas, gratuitas e de qualidade
- Integração Contínua Cloudless
- RSCSS
- Modelando o Context map do zero
- No Silver Bullet, de novo
- Arquitetura Lambda e Arquitetura Kappa
Trabalhando com cálculos diretamente na placa de vídeo
Comparando computação tradicional com a computação paralela massiva na placa de vídeo
Entendendo o Cenário
O C++ AMP é uma extensão do C++ para prover melhor aproveitamento do processador da placa de vídeo. O C++ AMP não é uma linguagem: são algumas bibliotecas de C++ que prontas para trabalhar com a placa de vídeo, intermediada pelo Direct X 11.
O computador pode ter vários aceleradores para cálculos matemáticos. O WARM é um acelerador emulado criado pela Microsoft. A placa de vídeo é outro. Como a placa de vídeo possui centenas de núcleos, o desempenho para cálculos paralelos é notavelmente maior do que o desempenho da CPU.
Em C++ escreve-se códigos com algumas alterações indicando que cálculos devem ser movidos para ser calculados na placa de vídeo e quais não vão. Existem códigos que facilitam esta sincronização.
O exemplo deste artigo é um algoritmo que realiza a multiplicação de matrizes quadradas com diferentes tamanhos. Um temporizador fica ligado enquanto a execução ocorre. Após isto tem-se o tempo necessário para execução direta na CPU, para execução direta na GPU.
Configuração do computador(CPU)
Este exemplo foi executado num notebook acer Intel Core i3 com 6 GB de memória RAM, rodando o Windows 8. Mais detalhes estão disponíveis a seguir:
Time of this report | 01/10/2013, 15:09:33 |
Operating System | Windows 8 Enterprise 64-bit (6.2, Build 9200) (9200.win8_gdr.130531-1504) |
Language | Portuguese (Regional Setting: Portuguese) |
System Manufacturer | Acer |
System Model | Aspire E1-471 |
BIOS | InsydeH2O Version 03.72.02V1.24 |
Processor | Intel(R) Core(TM) i3-2328M CPU @ 2.20GHz (4 CPUs), ~2.2GHz |
Memory | 6144MB RAM |
Available OS Memory | 5980MB RAM |
Page File | 4703MB used, 2236MB available |
DirectX Version | DirectX 11 |
System DPI Setting | 96 DPI (100 percent) |
DxDiag Version | 6.02.9200.16384 64bit Unicode |
Configuração da Placa gráfica (GPU)
A Placa de vídeo utilizada para o cálculo é uma Intel(R) HD Graphics 3000, onboard, comum de vários notebooks atuais do mercado. Para mais detalhes veja a seguir:
Card name | Intel(R) HD Graphics 3000 |
Manufacturer | Intel Corporation |
Chip type | Intel(R) HD Graphics Family |
DAC type | Internal |
Device Type | Full Device |
Display Memory | 1760 MB |
Dedicated Memory | 128 MB |
Shared Memory | 1632 MB |
Current Mode | 1366 x 768 (32 bit) (60Hz) |
Monitor Name | Monitor Genérico PnP |
Monitor Model | Unknown |
Monitor Id | AUO183C |
Native Mode | 1366 x 768(p) (60.098Hz) |
Output Type | Internal |
Driver File Version | 9.17.0010.2932 (English) |
Driver Version | 9.17.10.2932 |
Graphics Preemption | DMA |
Compute Preemption | DMA |
Driver Attributes | Final Retail |
Driver Date/Size | 12/14/2012 02:42:34, 12615680 bytes |
D3D9 Overlay | Supported |
DXVA-HD | Supported |
DDraw Status | Enabled |
D3D Status | Enabled |
AGP Status | Enabled |
Algorítmo
O algoritmo foi construído com base em exemplos disponíveis gratuitamente na internet e com base na minha experiência.
Multiplicação de matriz na CPU
Um método chamado multiply_matrix_cpué o responsável por realizar a multiplicação de matrizes na CPU.
 |
| Multiplicação de Matrizes pela CPU |
{kind=link}
Multiplicação de Matriz na GPU
Um método chamado multiply_matrix_gpué o responsável por realizar a multiplicação de matrizes na GPU.
 |
| Multiplicação de Matrizes pela GPU |
Método Principal
No método principal um temporizador é ligado antes e depois de cada execução. Foram separadas 3 execuções, uma para cada tipo: CPU e GPU. Na tela da aplicação o tempo corrido fica disponível.
Tempo de execução
A tabela a seguir é uma amostra de tempo em segundos para a execução.
| Tabela comparativa para multiplicação de matrizes na CPU e na GPU |
O gráfico valoriza a diferença de tempo de execução entre a CPU e a GPU. A execução na GPU mostra um desempenho mais acentuado quando comparada a CPU na matriz de 1024×1024 com a diferença de 12,1s entre a CPU e a GPU.
A execução tradicional da CPU mostrou-se o pior cenário. Chegando a 13940s (3,8 horas) para multiplicar uma matriz de 8192×8192 contra 9981,02s (2,7 horas) da GPU.
{kind=link}
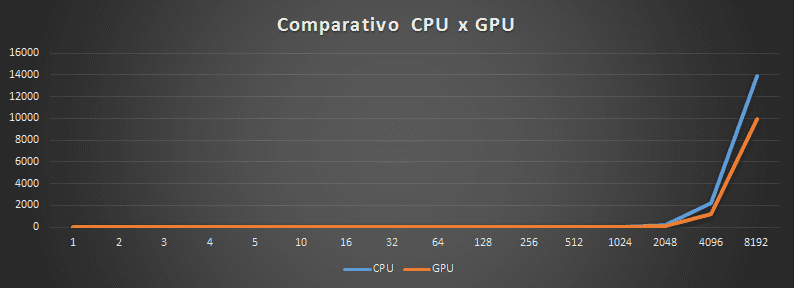 |
| Gráfico comparativo para multiplicação de matrizes na CPU e na GPU |
Conclusão
A utilização do C++ AMP para multiplicação de matrizes quadradas garante uma eficiência de até 1.1 hora para amostras grandes como 8192×8192, que é computado em quase 4 horas na CPU e em quase 3 horas na GPU.
Este exemplo mostra com clareza que a GPU possui considerável superioridade à CPU para realização de cálculos matemáticos.

Thiago Anselme - Gerente de TI - Arquiteto de Soluções
Ele atua/atuou como Dev Full Stack C# .NET / Angular / Kubernetes e afins. Ele possui certificações Microsoft MCTS (6x), MCPD em Web, ITIL v3 e CKAD (Kubernetes) . Thiago é apaixonado por tecnologia, entusiasta de TI desde a infância bem como amante de aprendizado contínuo.
